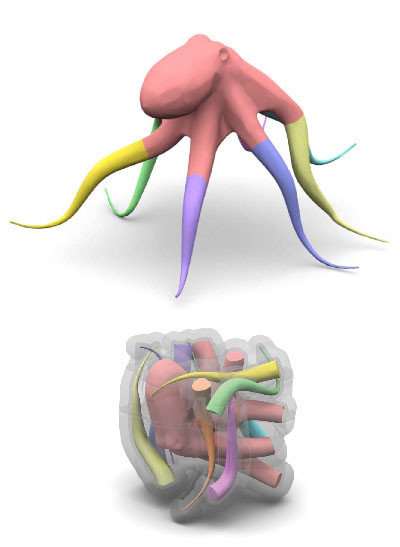
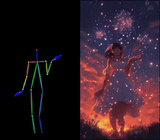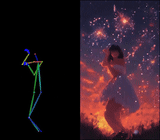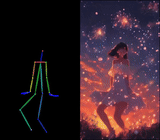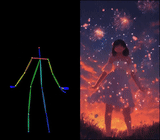The ability to synthesize personalized group photos and specify the positions of each identity offers immense creative potential. While such imagery can be visually appealing, it presents significant challenges for existing technologies. A persistent issue is identity (ID) leakage, where injected facial features interfere with one another, resulting in low face resemblance, incorrect positioning, and visual artifacts. Existing methods suffer from limitations such as the reliance on segmentation models, increased runtime, or a high probability of ID leakage. To address these challenges, we propose ID-Patch, a novel method that provides robust association between identities and 2D positions. Our approach generates an ID patch and ID embeddings from the same facial features: the ID patch is positioned on the conditional image for precise spatial control, while the ID embeddings integrate with text embeddings to ensure high resemblance. Experimental results demonstrate that ID-Patch surpasses baseline methods across metrics, such as face ID resemblance, ID-position association accuracy, and generation efficiency.
@article{25-IDPatch,author={Zhang, Yimeng and Zhi, Tiancheng and Liu, Jing and Sang, Shen and Jiang, Liming and Yan, Qing and Liu, Sijia and Luo, Linjie},title={ID-Patch: Robust ID Association for Group Photo Personalization},journal={Computer Vision and Pattern Recognition (CVPR)},year={2025},}
×
X-Dyna: Expressive Dynamic Human Image Animation
Di Chang, Hongyi Xu, You Xie, Yipeng Gao, Zhengfei Kuang, Chenxu Zhang Shengqu Cai, Guoxian Song, Chao Wang, Yichun Shi, Zeyuan Chen, Shijie Zhou, Linjie Luo, Gordon Wetzstein, and Mohammad Soleymani
Computer Vision and Pattern Recognition (CVPR), 2025
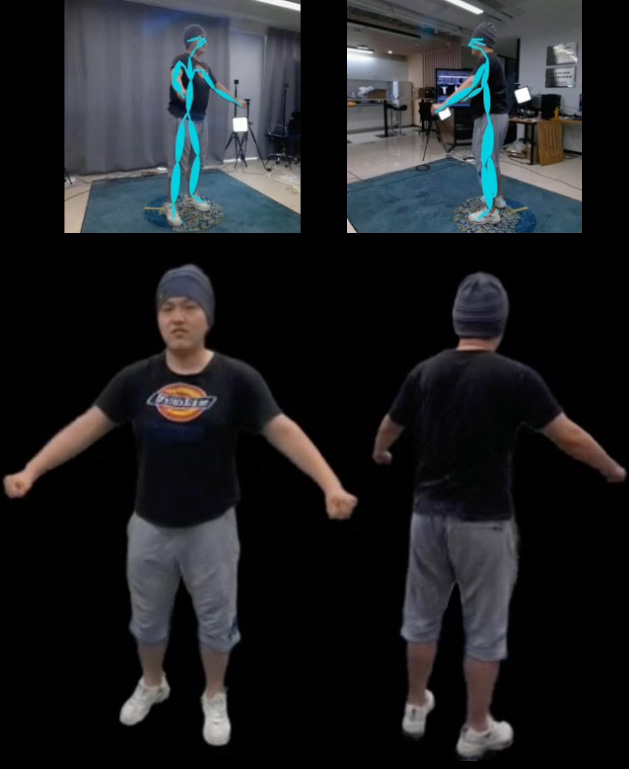
We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key factors underlying the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations.
@article{25-XDyna,author={Chang, Di and Xu, Hongyi and Xie, You and Gao, Yipeng and Kuang, Zhengfei and Shengqu Cai, Chenxu Zhang and Song, Guoxian and Wang, Chao and Shi, Yichun and Chen, Zeyuan and Zhou, Shijie and Luo, Linjie and Wetzstein, Gordon and Soleymani, Mohammad},title={X-Dyna: Expressive Dynamic Human Image Animation},journal={Computer Vision and Pattern Recognition (CVPR)},year={2025},}
×
COAP: Memory-Efficient Training with Correlation-Aware Gradient Projection
Jinqi Xiao, Shen Sang, Tiancheng Zhi, Jing Liu, Qing Yan, Linjie Luo, and Bo Yuan
Computer Vision and Pattern Recognition (CVPR), 2025
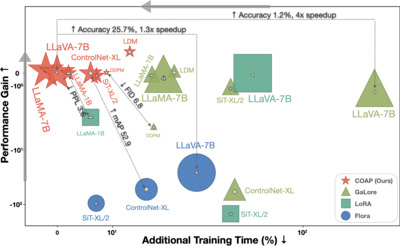
Training large-scale neural networks in vision, and multimodal domains demands substantial memory resources, primarily due to the storage of optimizer states. While LoRA, a popular parameter-efficient method, reduces memory usage, it often suffers from suboptimal performance due to the constraints of low-rank updates. Low-rank gradient projection methods (e.g., GaLore, Flora) reduce optimizer memory by projecting gradients and moment estimates into low-rank spaces via singular value decomposition or random projection. However, they fail to account for inter-projection correlation, causing performance degradation, and their projection strategies often incur high computational costs. In this paper, we present COAP (COrrelation-Aware Gradient Projection), a memory-efficient method that minimizes computational overhead while maintaining training performance. Evaluated across various vision, language, and multimodal tasks, COAP outperforms existing methods in both training speed and model performance. For LLaMA-1B, it reduces optimizer memory by 61% with only 2% additional time cost, achieving the same PPL as AdamW. With 8-bit quantization, COAP cuts optimizer memory by 81% and achieves 4x speedup over GaLore for LLaVA-v1.5-7B fine-tuning, while delivering higher accuracy.
@article{25-COAP,author={Xiao, Jinqi and Sang, Shen and Zhi, Tiancheng and Liu, Jing and Yan, Qing and Luo, Linjie and Yuan, Bo},title={COAP: Memory-Efficient Training with Correlation-Aware Gradient Projection},journal={Computer Vision and Pattern Recognition (CVPR)},year={2025},}
×
X-NeMo: Expressive Neural Motion Reenactment via Disentangled Latent Attention
Xiaochen Zhao, Hongyi Xu, Guoxian Song, You Xie, Chenxu Zhang, Xiu Li, Linjie Luo, Jinli Suo, and Yebin Liu
International Conference on Learning Representations(ICLR), 2025
We propose X-NeMo, a novel zero-shot diffusion-based portrait animation pipeline that animates a static portrait using facial movements from a driving video of a different individual. Our work first identifies the root causes of the limitations in prior approaches, such as identity leakage and difficulty in capturing subtle and extreme expressions. To address these challenges, we introduce a fully end-to-end training framework that distills a 1D identity-agnostic latent motion descriptor from driving image, effectively controlling motion through cross-attention during image generation. Our implicit motion descriptor captures expressive facial motion in fine detail, learned end-to-end from a diverse video dataset without reliance on any pre-trained motion detectors. We further disentangle motion latents from identity cues with enhanced expressiveness by supervising their learning with a dual GAN decoder, alongside spatial and color augmentations. By embedding the driving motion into a 1D latent vector and controlling motion via cross-attention instead of additive spatial guidance, our design effectively eliminates the transmission of spatial-aligned structural clues from the driving condition to the diffusion backbone, substantially mitigating identity leakage. Extensive experiments demonstrate that X-NeMo surpasses state-of-the-art baselines, producing highly expressive animations with superior identity resemblance. Our code and models will be available for research.
@article{25-XNeMo,author={Zhao, Xiaochen and Xu, Hongyi and Song, Guoxian and Xie, You and Zhang, Chenxu and Li, Xiu and Luo, Linjie and Suo, Jinli and Liu, Yebin},title={X-NeMo: Expressive Neural Motion Reenactment via Disentangled Latent Attention},journal={International Conference on Learning Representations(ICLR)},year={2025},}
2024
×
X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention
You Xie, Hongyi Xu, Guoxian Song, Chao Wang, Yichun Shi, and Linjie Luo
We propose X-Portrait, an innovative conditional diffusion model tailored for generating expressive and temporally coherent portrait animation. Specifically, given a single portrait as appearance reference, we aim to animate it with motion derived from a driving video, capturing both highly dynamic and subtle facial expressions along with wide-range head movements. As its core, we leverage the generative prior of a pre-trained diffusion model as the rendering backbone, while achieve fine-grained head pose and expression control with novel controlling signals within the framework of ControlNet. In contrast to conventional coarse explicit controls such as facial landmarks, our motion control module is learned to interpret the dynamics directly from the original driving RGB inputs. The motion accuracy is further enhanced with a patch-based local control module that effectively enhance the motion attention to small-scale nuances like eyeball positions. Notably, to mitigate the identity leakage from the driving signals, we train our motion control modules with scaling-augmented cross-identity images, ensuring maximized disentanglement from the appearance reference modules. Experimental results demonstrate the universal effectiveness of X-Portrait across a diverse range of facial portraits and expressive driving sequences, and showcase its proficiency in generating captivating portrait animations with consistently maintained identity characteristics.
@article{24-SIG-XPortrait,author={Xie, You and Xu, Hongyi and Song, Guoxian and Wang, Chao and Shi, Yichun and Luo, Linjie},title={X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention},year={2024},isbn={9798400705250},publisher={Association for Computing Machinery},address={New York, NY, USA},url={https://doi.org/10.1145/3641519.3657459},doi={10.1145/3641519.3657459},journal={ACM SIGGRAPH},articleno={115},numpages={11},keywords={ControlNet, generative model, portrait animation, stable diffusion, talking head},location={Denver, CO, USA},series={SIGGRAPH '24},}
×
Bridging Global Context Interactions for High-Fidelity Pluralistic Image Completion
We introduce PICFormer, a novel framework for P luralistic I mage C ompletion using a trans Former based architecture, that achieves both high quality and diversity at a much faster inference speed. Our key contribution is to introduce a code-shared codebook learning using a restrictive CNN on small and non-overlapping receptive fields (RFs) for the local visible token representation. This results in a compact yet expressive discrete representation, facilitating efficient modeling of global visible context relations by the transformer. Unlike the prevailing autoregressive approaches, we proposed to sample all tokens simultaneously, leading to more than 100× faster inference speed. To enhance appearance consistency between visible and generated regions, we further propose a novel attention-aware layer (AAL), designed to better exploit distantly related high-frequency features. Through extensive experiments, we demonstrate that the PICFormer efficiently learns semantically-rich discrete codes, resulting in significantly improved image quality. Moreover, our diverse image completion framework surpasses State-of-the-Art methods on multiple image completion datasets.
@article{24-TPAMI-PICFormer,author={Zheng, Chuanxia and Song, Guoxian and Cham, Tat-Jen and Cai, Jianfei and Luo, Linjie and Phung, Dinh},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI)},title={Bridging Global Context Interactions for High-Fidelity Pluralistic Image Completion},year={2024},volume={46},number={12},pages={8320-8333},}
×
DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
Yuming Gu, Hongyi Xu, You Xie, Guoxian Song, Yichun Shi, Di Chang, Jing Yang, and Linjie Luo
Computer Vision and Pattern Recognition (CVPR) (Highlight), Jun 2024
We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.
@article{24-CVPR-DiffPortrait3D,title={DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis},author={Gu, Yuming and Xu, Hongyi and Xie, You and Song, Guoxian and Shi, Yichun and Chang, Di and Yang, Jing and Luo, Linjie},year={2024},journal={Computer Vision and Pattern Recognition (CVPR) (Highlight)},month=jun,}
2023
×
HVTR++: Image and Pose Driven Human Avatars using Hybrid Volumetric Textural Rendering
Tao Hu, Hongyi Xu, Linjie Luo, Tao Yu, Zerong Zheng, He Zhang, Yebin Liu, and Matthias Zwicker
IEEE Transactions on Visualization and Computer Graphics (TVCG), 2023
Recent neural rendering methods have made great progress in generating photorealistic human avatars. However, these methods are generally conditioned only on low-dimensional driving signals (e.g., body poses), which are insufficient to encode the complete appearance of a clothed human. Hence they fail to generate faithful details. To address this problem, we exploit driving view images (e.g., in telepresence systems) as additional inputs. We propose a novel neural rendering pipeline, Hybrid Volumetric-Textural Rendering (HVTR++), which synthesizes 3D human avatars from arbitrary driving poses and views while staying faithful to appearance details efficiently and at high quality. First, we learn to encode the driving signals of pose and view image on a dense UV manifold of the human body surface and extract UV-aligned features, preserving the structure of a skeleton-based parametric model. To handle complicated motions (e.g., self-occlusions), we then leverage the UV-aligned features to construct a 3D volumetric representation based on a dynamic neural radiance field. While this allows us to represent 3D geometry with changing topology, volumetric rendering is computationally heavy. Hence we employ only a rough volumetric representation using a pose- and image-conditioned downsampled neural radiance field (PID-NeRF), which we can render efficiently at low resolutions. In addition, we learn 2D textural features that are fused with rendered volumetric features in image space. The key advantage of our approach is that we can then convert the fused features into a high-resolution, high-quality avatar by a fast GAN-based textural renderer. We demonstrate that hybrid rendering enables HVTR++ to handle complicated motions, render high-quality avatars under user-controlled poses/shapes, and most importantly, be efficient at inference time. Our experimental results also demonstrate state-of-the-art quantitative results.
@article{23-TVCG-HVTR++,author={Hu, Tao and Xu, Hongyi and Luo, Linjie and Yu, Tao and Zheng, Zerong and Zhang, He and Liu, Yebin and Zwicker, Matthias},journal={IEEE Transactions on Visualization and Computer Graphics (TVCG)},title={HVTR++: Image and Pose Driven Human Avatars using Hybrid Volumetric Textural Rendering},year={2023},url={https://dl.acm.org/doi/10.1109/TVCG.2023.3297721},}
×
PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360
Sizhe An, Hongyi Xu, Yichun Shi, Guoxian Song, Umit Ogras, and Linjie Luo
Computer Vision and Pattern Recognition (CVPR), Jun 2023
Synthesis and reconstruction of 3D human head has gained increasing interests in computer vision and computer graphics recently. Existing state-of-the-art 3D generative adversarial networks (GANs) for 3D human head synthesis are either limited to near-frontal views or hard to preserve 3D consistency in large view angles. We propose PanoHead, the first 3D-aware generative model that enables high-quality view-consistent image synthesis of full heads in 360° with diverse appearance and detailed geometry using only in-the-wild unstructured images for training. At its core, we lift up the representation power of recent 3D GANs and bridge the data alignment gap when training from in-the-wild images with widely distributed views. Specifically, we propose a novel two-stage self-adaptive image alignment for robust 3D GAN training. We further introduce a tri-grid neural volume representation that effectively addresses front-face and back-head feature entanglement rooted in the widely-adopted tri-plane formulation. Our method instills prior knowledge of 2D image segmentation in adversarial learning of 3D neural scene structures, enabling compositable head synthesis in diverse backgrounds. Benefiting from these designs, our method significantly outperforms previous 3D GANs, generating high-quality 3D heads with accurate geometry and diverse appearances, even with long wavy and afro hairstyles, renderable from arbitrary poses. Furthermore, we show that our system can reconstruct full 3D heads from single input images for personalized realistic 3D avatars.
@article{23-CVPR-OmniAvatar,title={PanoHead: Geometry-Aware 3D Full-Head Synthesis in 360},author={An, Sizhe and Xu, Hongyi and Shi, Yichun and Song, Guoxian and Ogras, Umit and Luo, Linjie},journal={Computer Vision and Pattern Recognition (CVPR)},year={2023},month=jun,}
×
OmniAvatar: Geometry-Guided Controllable 3D Head Synthesis
Hongyi Xu, Guoxian Song, Zihang Jiang, Jianfeng Zhang, Yichun Shi, Jing Liu, Wanchun Ma, Jiashi Feng, and Linjie Luo
Computer Vision and Pattern Recognition (CVPR), Jun 2023
We present OmniAvatar, a novel geometry-guided 3D head synthesis model trained from in-the-wild unstructured images that is capable of synthesizing diverse identity-preserved 3D heads with compelling dynamic details under full disentangled control over camera poses, facial expressions, head shapes, articulated neck and jaw poses. To achieve such high level of disentangled control, we first explicitly define a novel semantic signed distance function (SDF) around a head geometry (FLAME) conditioned on the control parameters. This semantic SDF allows us to build a differentiable volumetric correspondence map from the observation space to a disentangled canonical space from all the control parameters. We then leverage the 3D-aware GAN framework (EG3D) to synthesize detailed shape and appearance of 3D full heads in the canonical space, followed by a volume rendering step guided by the volumetric correspondence map to output into the observation space. To ensure the control accuracy on the synthesized head shapes and expressions, we introduce a geometry prior loss to conform to head SDF and a control loss to conform to the expression code. Further, we enhance the temporal realism with dynamic details conditioned upon varying expressions and joint poses. Our model can synthesize more preferable identity-preserved 3D heads with compelling dynamic details compared to the state-of-the-art methods both qualitatively and quantitatively. We also provide an ablation study to justify many of our system design choices.
@article{23-CVPR-OmniAvatas,author={Xu, Hongyi and Song, Guoxian and Jiang, Zihang and Zhang, Jianfeng and Shi, Yichun and Liu, Jing and Ma, Wanchun and Feng, Jiashi and Luo, Linjie},title={OmniAvatar: Geometry-Guided Controllable 3D Head Synthesis},journal={Computer Vision and Pattern Recognition (CVPR)},year={2023},month=jun,}
2022
×
AgileAvatar: Stylized 3D Avatar Creation via Cascaded Domain Bridging
Shen Sang, Tiancheng Zhi, Guoxian Song, Minghao Liu, Chunpong Lai, Jing Liu, Xiang Wen, James Davis, and Linjie Luo
Stylized 3D avatars have become increasingly prominent in our modern life. Creating these avatars manually usually involves laborious selection and adjustment of continuous and discrete parameters and is time-consuming for average users. Self-supervised approaches to automatically create 3D avatars from user selfies promise high quality with little annotation cost but fall short in application to stylized avatars due to a large style domain gap. We propose a novel self-supervised learning framework to create high-quality stylized 3D avatars with a mix of continuous and discrete parameters. Our cascaded domain bridging framework first leverages a modified portrait stylization approach to translate input selfies into stylized avatar renderings as the targets for desired 3D avatars. Next, we find the best parameters of the avatars to match the stylized avatar renderings through a differentiable imitator we train to mimic the avatar graphics engine. To ensure we can effectively optimize the discrete parameters, we adopt a cascaded relaxation-and-search pipeline. We use a human preference study to evaluate how well our method preserves user identity compared to previous work as well as manual creation. Our results achieve much higher preference scores than previous work and close to those of manual creation. We also provide an ablation study to justify the design choices in our pipeline.
@article{22-SIGA-AgileAvatar,author={Sang, Shen and Zhi, Tiancheng and Song, Guoxian and Liu, Minghao and Lai, Chunpong and Liu, Jing and Wen, Xiang and Davis, James and Luo, Linjie},title={AgileAvatar: Stylized 3D Avatar Creation via Cascaded Domain Bridging},year={2022},isbn={9781450394703},publisher={Association for Computing Machinery},address={New York, NY, USA},journal={SIGGRAPH Asia},articleno={23},numpages={8},keywords={Avatar Creation, Human Stylization},location={Daegu, Republic of Korea},series={SA '22},}
2021
×
AgileGAN: Stylizing Portraits by Inversion-Consistent Transfer Learning
Portraiture as an art form has evolved from realistic depiction into a plethora of creative styles. While substantial progress has been made in automated stylization, generating high quality stylistic portraits is still a challenge, and even the recent popular Toonify suffers from several artifacts when used on real input images. Such StyleGAN-based methods have focused on finding the best latent inversion mapping for reconstructing input images; however, our key insight is that this does not lead to good generalization to different portrait styles. Hence we propose AgileGAN, a framework that can generate high quality stylistic portraits via inversion-consistent transfer learning. We introduce a novel hierarchical variational autoencoder to ensure the inverse mapped distribution conforms to the original latent Gaussian distribution, while augmenting the original space to a multi-resolution latent space so as to better encode different levels of detail. To better capture attributedependent stylization of facial features, we also present an attribute-aware generator and adopt an early stopping strategy to avoid overfitting small training datasets. Our approach provides greater agility in creating high quality and high resolution (1024×1024) portrait stylization models, requiring only a limited number of style exemplars (∼100) and short training time (∼1 hour). We collected several style datasets for evaluation including 3D cartoons, comics, oil paintings and celebrities. We show that we can achieve superior portrait stylization quality to previous state-of-the-art methods, with comparisons done qualitatively, quantitatively and through a perceptual user study. We also demonstrate two applications of our method, image editing and motion retargeting.
@article{21-SIG-AgileGAN,author={Song, Guoxian and Luo, Linjie and Liu, Jing and Ma, Wan-Chun and Lai, Chunpong and Zheng, Chuanxia and Cham, Tat-Jen},title={AgileGAN: Stylizing Portraits by Inversion-Consistent Transfer Learning},journal={ACM Transactions on Graphics (Proc. SIGGRAPH)},year={2021},month=aug,volume={37},number={4},}
2020
×
HoliCity: A City-Scale Data Platform for Learning Holistic 3D Structures
Yichao Zhou, Jingwei Huang, Xili Dai, Linjie Luo, Zhili Chen, and Yi Ma
We present HoliCity, a city-scale 3D dataset with rich structural information. Currently, this dataset has 6,300 real-world panoramas of resolution 13312 × 6656 that are accurately aligned with the CAD model of downtown London with an area of more than 20 km2, in which the median reprojection error of the alignment of an average image is less than half a degree. This dataset aims to be an all-in- one data platform for research of learning abstracted high-level holistic 3D structures that can be derived from city CAD models, e.g., corners, lines, wireframes, planes, and cuboids, with the ultimate goal of supporting real-world applications including city-scale reconstruction, localization, mapping, and augmented reality. The accurate alignment of the 3D CAD models and panoramas also benefits low-level 3D vision tasks such as surface normal estimation, as the surface normal extracted from previous LiDAR-based datasets is often noisy. We conduct experiments to demonstrate the applications of HoliCity, such as predicting surface segmentation, normal maps, depth maps, and vanishing points, as well as test the generalizability of methods trained on HoliCity and other related datasets. HoliCity is available at https://holicity.io.
@article{20-HoliCity,author={Zhou, Yichao and Huang, Jingwei and Dai, Xili and Luo, Linjie and Chen, Zhili and Ma, Yi},title={HoliCity: A City-Scale Data Platform for Learning Holistic 3D Structures},journal={ICCV Workshop},year={2020},}
×
DynOcc: Learning Single-View Depth from Dynamic Occlusion Cues
Yifan Wang, Linjie Luo, Xiaohui Shen, and Xing Mei
Recently, significant progress has been made in single-view depth estimation thanks to increasingly large and diverse depth datasets. However, these datasets are largely limited to specific application domains (e.g. indoor, autonomous driving) or static in-the-wild scenes due to hard-ware constraints or technical limitations of 3D reconstruction. In this paper, we introduce the first depth dataset DynOcc consisting of dynamic in-the-wild scenes. Our approach leverages the occlusion cues in these dynamic scenes to infer depth relationships between points of selected video frames. To achieve accurate occlusion detection and depth order estimation, we employ a novel occlusion boundary detection, filtering and thinning scheme followed by a robust foreground/background classification method. In total our DynOcc dataset contains 22M depth pairs out of 91K frames from a diverse set of videos. Using our dataset we achieved state-of-the-art results measured in weighted human disagreement rate (WHDR). We also show that the inferred depth maps trained with DynOcc can preserve sharper depth boundaries.
@article{20-3DV-DynOcc,author={Wang, Yifan and Luo, Linjie and Shen, Xiaohui and Mei, Xing},title={DynOcc: Learning Single-View Depth from Dynamic Occlusion Cues},journal={International Conference on 3D Vision (3DV)},year={2020},}
×
Deep Generative Modeling for Scene Synthesis via Hybrid Representations
Zaiwei Zhang, Zhenpei Yang, Chongyang Ma, Linjie Luo, Alexander Huth, Etienne Vouga, and Qixing Huang
We present a deep generative scene modeling technique for indoor environments. Our goal is to train a generative model using a feed-forward neural network that maps a prior distribution (e.g., a normal distribution) to the distribution of primary objects in indoor scenes. We introduce a 3D object arrangement representation that models the locations and orientations of objects, based on their size and shape attributes. Moreover, our scene representation is applicable for 3D objects with different multiplicities (repetition counts), selected from a database. We show a principled way to train this model by combining discriminative losses for both a 3D object arrangement representation and a 2D image-based representation. We demonstrate the effectiveness of our scene representation and the network training method
@article{20-TOG-SceneGen,author={Zhang, Zaiwei and Yang, Zhenpei and Ma, Chongyang and Luo, Linjie and Huth, Alexander and Vouga, Etienne and Huang, Qixing},title={Deep Generative Modeling for Scene Synthesis via Hybrid Representations},journal={ACM Transactions on Graphics},year={2020},month=apr,volume={39},number={2},}
2019
×
Transformable Bottleneck Networks
Kyle Olszewski, Sergey Tulyakov, Oliver Woodford, Hao Li, and Linjie Luo
IEEE International Conference on Computer Vision (ICCV), 2019
We propose a novel approach to performing fine-grained 3D manipulation of image content via a convolutional neural network, which we call the Transformable Bottleneck Network (TBN). It applies given spatial transformations directly to a volumetric bottleneck within our encoder-bottleneck-decoder architecture. Multi-view supervision encourages the network to learn to spatially disentangle the feature space within the bottleneck. The resulting spatial structure can be manipulated with arbitrary spatial transformations. We demonstrate the efficacy of TBNs for novel view synthesis, achieving state-of-the-art results on a challenging benchmark. We demonstrate that the bottlenecks produced by networks trained for this task contain meaningful spatial structure that allows us to intuitively perform a variety of image manipulations in 3D, well beyond the rigid transformations seen during training. These manipulations include non-uniform scaling, non-rigid warping, and combining content from different images. Finally, we extract explicit 3D structure from the bottleneck, performing impressive 3D reconstruction from a single input image.
@article{19-ICCV-TBN,author={Olszewski, Kyle and Tulyakov, Sergey and Woodford, Oliver and Li, Hao and Luo, Linjie},title={Transformable Bottleneck Networks},journal={IEEE International Conference on Computer Vision (ICCV)},year={2019},}
×
Dynamic Kernel Distillation for Efficient Pose Estimation in Videos
Xuecheng Nie, Yuncheng Li, Linjie Luo, Ning Zhang, and Jiashi Feng
IEEE International Conference on Computer Vision (ICCV), 2019
Existing video-based human pose estimation methods extensively apply large networks onto every frame in the video to localize body joints, which suffer high computational cost and hardly meet the low-latency requirement in realistic applications. To address this issue, we propose a novel Dynamic Kernel Distillation (DKD) model to facilitate small networks for estimating human poses in videos, thus significantly lifting the efficiency. In particular, DKD introduces a light-weight distillator to online distill pose kernels via leveraging temporal cues from the previous frame in a one-shot feed-forward manner. Then, DKD simplifies body joint localization into a matching procedure between the pose kernels and the current frame, which can be efficiently computed via simple convolution. In this way, DKD fast transfers pose knowledge from one frame to provide compact guidance for body joint localization in the following frame, which enables utilization of small networks in video-based pose estimation. To facilitate the training process, DKD exploits a temporally adversarial training strategy that introduces a temporal discriminator to help generate temporally coherent pose kernels and pose estimation results within a long range. Experiments on Penn Action and Sub-JHMDB benchmarks demonstrate outperforming efficiency of DKD, specifically, 10x flops reduction and 2x speedup over previous best model, and its state-of-the-art accuracy.
@article{19-ICCV-KernelPose,author={Nie, Xuecheng and Li, Yuncheng and Luo, Linjie and Zhang, Ning and Feng, Jiashi},title={Dynamic Kernel Distillation for Efficient Pose Estimation in Videos},journal={IEEE International Conference on Computer Vision (ICCV)},year={2019},}
×
Extreme Relative Pose Estimation for RGB-D Scans via Scene Completion
Zhenpei Yang, Jeffrey Z.Pan, Linjie Luo, Xiaowei Zhou, Kristen Grauman, and Qixing Huang
Computer Vision and Pattern Recognition (CVPR), Jun 2019
Estimating the relative rigid pose between two RGB-D scans of the same underlying environment is a fundamental problem in computer vision, robotics, and computer graphics. Most existing approaches allow only limited relative pose changes since they require considerable overlap between the input scans. We introduce a novel approach that extends the scope to extreme relative poses, with little or even no overlap between the input scans. The key idea is to infer more complete scene information about the underlying environment and match on the completed scans. In particular, instead of only performing scene completion from each individual scan, our approach alternates between relative pose estimation and scene completion. This allows us to perform scene completion by utilizing information from both input scans at late iterations, resulting in better results for both scene completion and relative pose estimation. Experimental results on benchmark datasets show that our approach leads to considerable improvements over state-of- the-art approaches for relative pose estimation. In particular, our approach provides encouraging relative pose estimates even between non-overlapping scans.
@article{19-CVPR-ExtremePose,author={Yang, Zhenpei and Z.Pan, Jeffrey and Luo, Linjie and Zhou, Xiaowei and Grauman, Kristen and Huang, Qixing},title={Extreme Relative Pose Estimation for RGB-D Scans via Scene Completion},journal={Computer Vision and Pattern Recognition (CVPR)},year={2019},month=jun,}
2018
×
Stabilized Real-time Face Tracking via a Learned Dynamic Rigidity Prior
Chen Cao, Menglei Chai, Oliver Woodford, and Linjie Luo
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), Nov 2018
Despite the popularity of real-time monocular face tracking systems in many successful applications, one overlooked problem with these systems is rigid instability. It occurs when the input facial motion can be explained by either head pose change or facial expression change, creating ambiguities that often lead to jittery and unstable rigid head poses under large expressions. Existing rigid stabilization methods either employ a heavy anatomically-motivated approach that are unsuitable for real-time applications, or utilize heuristic-based rules that can be problematic under certain expressions. We propose the first rigid stabilization method for real-time monocular face tracking using a dynamic rigidity prior learned from realistic datasets. The prior is defined on a region-based face model and provides dynamic region-based adaptivity for rigid pose optimization during real-time performance. We introduce an effective offline training scheme to learn the dynamic rigidity prior by optimizing the convergence of the rigid pose optimization to the ground-truth poses in the training data. Our real-time face tracking system is an optimization framework that alternates between rigid pose optimization and expression optimization. To ensure tracking accuracy, we combine both robust, drift-free facial landmarks and dense optical flow into the optimization objectives. We evaluate our system extensively against state-of-the-art monocular face tracking systems and achieve significant improvement in tracking accuracy on the high-quality face tracking benchmark. Our system can improve facial-performance-based applications such as facial animation retargeting and virtual face makeup with accurate expression and stable pose. We further validate the dynamic rigidity prior by comparing it against other variants on the tracking accuracy.
@article{18-SIG-Stabilized,author={Cao, Chen and Chai, Menglei and Woodford, Oliver and Luo, Linjie},title={Stabilized Real-time Face Tracking via a Learned Dynamic Rigidity Prior},journal={ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},year={2018},month=nov,volume={37},number={6},}
×
3D Hair Synthesis Using Volumetric Variational Autoencoders
Shunsuke Saito, Liwen Hu, Chongyang Ma, Linjie Luo, and Hao Li
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), Nov 2018
Recent advances in single-view 3D hair digitization have made the creation of high-quality CG characters scalable and accessible to end-users, enabling new forms of personalized VR and gaming experiences. To handle the complexity and variety of hair structures, most cutting-edge techniques rely on the successful retrieval of a particular hair model from a comprehensive hair database. Not only are the aforementioned data-driven methods storage intensive, but they are also prone to failure for highly unconstrained input images, exotic hairstyles, failed face detection. Instead of using a large collection of 3D hair models directly, we propose to represent the manifold of 3D hairstyles implicitly through a compact latent space of a volumetric variational autoencoder (VAE). This deep neural network is trained with volumetric orientation field representations of 3D hair models and can synthesize new hairstyles from a compressed code. To enable end-to-end 3D hair inference, we train an additional regression network to predict the codes in the VAE latent space from any input image. Strand-level hairstyles can then be generated from the predicted volumetric representation. Our fully automatic framework does not require any ad-hoc face fitting, intermediate classification and segmentation, or hairstyle database retrieval. Our hair synthesis approach is significantly more robust than and can handle a much wider variation of hairstyles than state-of-the-art data-driven hair modeling techniques w.r.t. challenging inputs, including photos that are low-resolution, over-exposed, or contain extreme head poses. The storage requirements are minimal and a 3D hair model can be produced from an image in a second. Our evaluations also show that successful reconstructions are possible from highly stylized cartoon images, non-human subjects, and pictures taken from the back of a person. Our approach is particularly well suited for continuous and plausible hair interpolation between very different hairstyles.
@article{18-SIG-3DHairVAE,author={Saito, Shunsuke and Hu, Liwen and Ma, Chongyang and Luo, Linjie and Li, Hao},journal={ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},year={2018},month=nov,volume={37},number={6},}
×
Unsupervised Domain Adaptation for 3D Keypoint Estimation via View Consistency
In this paper, we introduce a novel unsupervised domain adaptation technique for the task of 3D keypoint prediction from a single depth scan/image. Our key idea is to utilize the fact that predictions from different views of the same or similar objects should be consistent with each other. Such view consistency provides effective regularization for keypoint prediction on unlabeled instances. In addition, we introduce a geometric alignment term to regularize predictions in the target domain. The resulting loss function can be effectively optimized via alternating minimization. We demonstrate the effectiveness of our approach on real datasets and present experimental results showing that our approach is superior to state-of-the-art general-purpose domain adaptation techniques.
@article{18-ECCV-3DKeypointDA,title={Unsupervised Domain Adaptation for 3D Keypoint Estimation via View Consistency},author={Zhou, Xingyi and Karpur, Arjun and Gan, Chuang and Luo, Linjie and Huang, Qixing},journal={European Conference on Computer Vision (ECCV)},year={2018},}
×
StarMap for Category-Agnostic Semantic Keypoint Representations in Canonical Object Views
Xingyi Zhou, Arjun Karpur, Linjie Luo, and Qixing Huang
European Conference on Computer Vision (ECCV), 2018
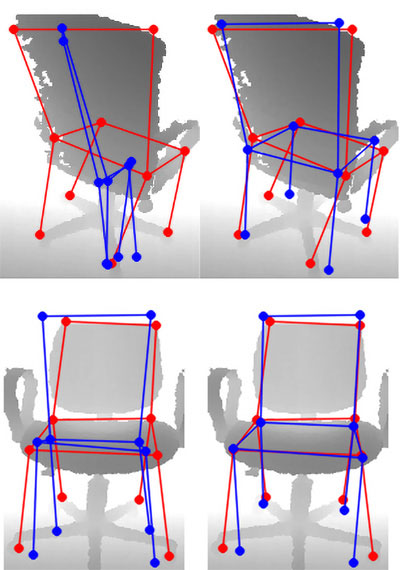
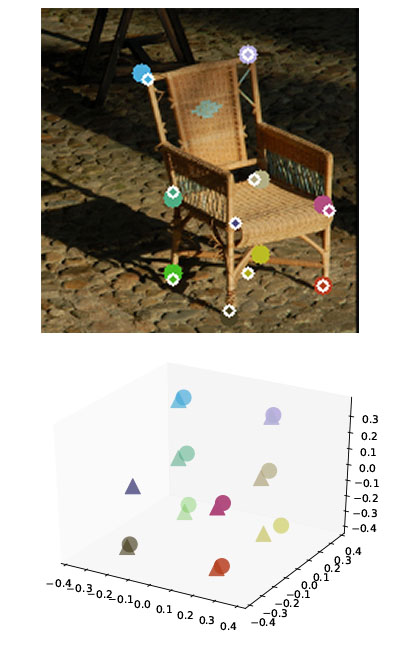
Semantic keypoints provide concise abstractions for a variety of visual understanding tasks. Existing methods define semantic keypoints separately for each category with a fixed number of semantic labels.
As a result, these keypoints are not suitable when objects have a varying number of parts, e.g. chairs with varying number of legs. We propose a category-agnostic keypoint representation encoded with their 3D locations in the canonical object views. Our intuition is that the 3D locations of the keypoints in canonical object views contain rich semantic and compositional information. Our representation thus consists of a single channel, multi-peak heatmap (StarMap) for all the keypoints and their corresponding features as 3D locations in the canonical object view (CanViewFeature) defined for each category. Not only is our representation flexible, but we also demonstrate competitive performance in keypoint detection and localization compared to category-specific state-of-the-art methods. Moreover, we show that when augmented with an additional depth channel (DepthMap) to lift the 2D keypoints to 3D,our representation can achieve state-of-the-art results in viewpoint estimation. Finally, we demonstrate that each individual component of our framework can be used on the task of human pose estimation to simplify the state-of-the-art architectures.
@article{18-ECCV-StarMap,title={StarMap for Category-Agnostic Semantic Keypoint Representations in Canonical Object Views},author={Zhou, Xingyi and Karpur, Arjun and Luo, Linjie and Huang, Qixing},journal={European Conference on Computer Vision (ECCV)},year={2018},}
×
Deep Volumetric Video From Very Sparse Multi-View Performance Capture
Zeng Huang, Tianye Li, Weikai Chen, Yajie Zhao, Jun Xing, Chloe LeGendre, Chongyang Ma, Linjie Luo, and Hao Li
European Conference on Computer Vision (ECCV), 2018
We present a deep learning-based volumetric capture approach for performance capture using a passive and highly sparse multi-view capture system. We focus on a template-free, per-frame 3D surface reconstruction from as few as three RGB sensors, where conventional visual hull or multi-view stereo methods would fail. State-of-the-art performance capture systems require either pre-scanned actors, large number of cameras or active sensors. We introduce a novel multi-view Convolutional Neural Network (CNN) that maps 2D images to a 3D volumetric field that encodes the probabilistic distribution of surface points of the captured subject. By querying the resulting field, we can instantiate the clothed human body at arbitrary resolutions. Our approach also scales to different numbers of input images, which yield increased reconstruction quality when more views are used. Though only trained on synthetic data, our network can generalize to real captured performances. Since high-quality temporal surface reconstructions are possible, our method is suitable for low-cost full body volumetric capture solutions for consumers, which are gaining popularity for VR and AR content creation. Experimental results demonstrate that our method is significantly more robust and accurate than existing techniques where only very sparse views are available.
@article{18-ECCV-VerySparseVol,title={Deep Volumetric Video From Very Sparse Multi-View Performance Capture},author={Huang, Zeng and Li, Tianye and Chen, Weikai and Zhao, Yajie and Xing, Jun and LeGendre, Chloe and Ma, Chongyang and Luo, Linjie and Li, Hao},journal={European Conference on Computer Vision (ECCV)},year={2018},}
2017
×
AutoScaler: Scale-Attention Networks for Visual Correspondence
Shenlong Wang, Linjie Luo, Ning Zhang, and Li-Jia Li
Finding visual correspondence between local features is key to many computer vision problems. While defining features with larger contextual scales usually implies greater discriminativeness, it could also lead to less spatial accuracy of the features. We propose AutoScaler, a scale-attention network to explicitly optimize this trade-off in visual correspondence tasks. Our architecture consists of a weight-sharing feature network to compute multi-scale feature maps and an attention network to combine them optimally in the scale space. This allows our network to have adaptive sizes of equivalent receptive field over different scales of the input. The entire network can be trained end-to-end in a Siamese framework for visual correspondence tasks. Using the latest off-the-shelf architecture for the feature network, our method achieves competitive results compared to state-of-the-art methods on challenging optical flow and semantic matching bench- marks, including Sintel, KITTI and CUB-2011. We also show that our attention network alone can be applied to existing hand-crafted feature descriptors (e.g Daisy) and improve their performance on visual correspondence tasks. Finally, we illustrate how the scale- attention maps generated from the attention network are visually interpretable.
@article{17-BMVC-AutoScaler,title={AutoScaler: Scale-Attention Networks for Visual Correspondence},author={Wang, Shenlong and Luo, Linjie and Zhang, Ning and Li, Li-Jia},journal={BMVC},year={2017},}
2016
×
Customized expression recognition for performance-driven cutout character animation
Xiang Yu, Jianchao Yang, Linjie Luo, Wilmot Li, Jonathan Brandt, and Dimitris Metaxas
IEEE Winter Conference on Applications of Computer Vision (WACV), Mar 2016
Performance-driven character animation enables users to create expressive results by performing the desired motion of the character with their face and/or body. How- ever, for cutout animations where continuous motion is combined with discrete artwork replacements, supporting a performance-driven workflow has some unique requirements. To trigger the appropriate artwork replacements, the system must reliably detect a wide range of customized facial expressions that are challenging for existing recognition methods, which focus on a few canonical expressions (e.g., angry, disgusted, scared, happy, sad and surprised). Also, real usage scenarios require the system to work in realtime with minimal training. In this paper, we propose a novel customized expression recognition technique that meets all of these requirements. We first use a set of handcrafted features combining geometric features derived from facial landmarks and patch-based appearance features through group sparsity- based facial component learning. To improve discrimination and generalization, these handcrafted features are integrated into a custom-designed Deep Convolutional Neural Network (CNN) structure trained from publicly available facial expression datasets. The combined features are fed to an online ensemble of SVMs designed for the few train- ing sample problem and performs in realtime. To improve temporal coherence, we also apply a Hidden Markov Mod- el (HMM) to smooth the recognition results. Our system achieves state-of-the-art performance on canonical expression datasets and promising results on our collected dataset of customized expressions.
@article{16-WACV-CustomExpr,author={Yu, Xiang and Yang, Jianchao and Luo, Linjie and Li, Wilmot and Brandt, Jonathan and Metaxas, Dimitris},journal={IEEE Winter Conference on Applications of Computer Vision (WACV)},title={Customized expression recognition for performance-driven cutout character animation},year={2016},pages={1-9},month=mar,}
2015
×
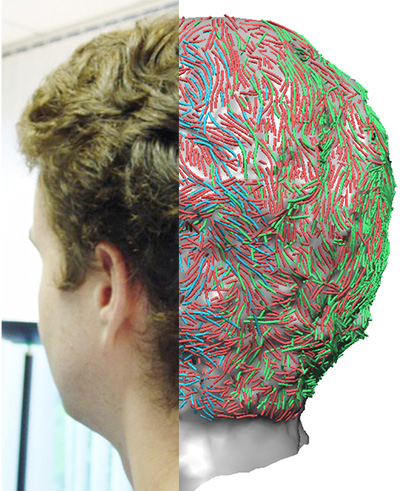
High-Quality Hair Modeling from A Single Portrait Photo
Menglei Chai, Linjie Luo, Kalyan Sunkavalli, Nathan Carr, Sunil Hadap, and Kun Zhou
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), Nov 2015
We propose a novel system to reconstruct a high-quality hair depth map from a single portrait photo with minimal user input. We achieve this by combining depth cues such as occlusions, silhouettes, and shading, with a novel 3D helical structural prior for hair reconstruction. We fit a parametric morphable face model to the input photo and construct a base shape in the face, hair and body regions using occlusion and silhouette constraints. We then estimate the normals in the hair region via a Shape-from-Shading-based optimization that uses the lighting inferred from the face model and enforces an adaptive albedo prior that models the typical color and occlusion variations of hair. We introduce a 3D helical hair prior that captures the geometric structure of hair, and show that it can be robustly recovered from the input photo in an automatic manner. Our system combines the base shape, the normals estimated by Shape from Shading, and the 3D helical hair prior to reconstruct high-quality 3D hair models. Our single-image reconstruction closely matches the results of a state-of-the-art multi-view stereo applied on a multi-view stereo dataset. Our technique can reconstruct a wide variety of hairstyles ranging from short to long and from straight to messy, and we demonstrate the use of our 3D hair models for high-quality portrait relighting, novel view synthesis and 3D-printed portrait reliefs.
@article{15-SIGA-HairRelief,author={Chai, Menglei and Luo, Linjie and Sunkavalli, Kalyan and Carr, Nathan and Hadap, Sunil and Zhou, Kun},title={High-Quality Hair Modeling from A Single Portrait Photo},journal={ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},year={2015},month=nov,volume={34},number={6},}
×
Level-Set-Based Partitioning and Packing Optimization of a Printable Model
Miaojun Yao, Zhili Chen, Linjie Luo, Rui Wang, and Huamin Wang
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), Nov 2015
As the 3D printing technology starts to revolutionize our daily life and the manufacturing industries, a critical problem is about to emerge: how can we find an automatic way to divide a 3D model into multiple printable pieces, so as to save the space, to reduce the printing time, or to make a large model printable by small printers. In this paper, we present a systematic study on the partitioning and packing of 3D models under the multi-phase level set framework. We first construct analysis tools to evaluate the qualities of a partitioning using six metrics: stress load, surface details, interface area, packed size, printability, and assembling. Based on this analysis, we then formulate level set methods to improve the qualities of the partitioning according to the metrics. These methods are integrated into an automatic system, which repetitively and locally optimizes the partitioning. Given the optimized partitioning result, we further provide a container structure modeling algorithm to facilitate the packing process of the printed pieces. Our experiment shows that the system can generate quality partitioning of various 3D models for space saving and fast production purposes.
@article{15-SIGA-LevelSetPrintable,author={Yao, Miaojun and Chen, Zhili and Luo, Linjie and Wang, Rui and Wang, Huamin},title={Level-Set-Based Partitioning and Packing Optimization of a Printable Model},journal={ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},year={2015},month=nov,volume={34},number={6},}
×
Single-View Hair Modeling Using A Hairstyle Database
Liwen Hu, Chongyang Ma, Linjie Luo, and Hao Li
ACM Transactions on Graphics (Proc. SIGGRAPH), Aug 2015
Hair digitalization has been one of the most critical and challenging tasks necessary to create virtual avatars. Most existing hair modeling techniques require either expensive capture devices or tedious manual effort. In this paper, we present a data-driven approach to create a complex 3D hairstyle from the single view of a photograph. We first build a database of 343 manually created 3D example hairstyles from some online repositories. Given a reference photo of the target hairstyle and a few user strokes as guidance, we automatically search for several best matching examples from the database and consistently combine them into a single hairstyle as the large-scale structure of the modeling output. Then we synthesize the final strands by ensuring the projected 2D similarity with the reference photo, the 3D physical plausibility of each individual strand as well as the local orientational coherency between neighboring strands simultaneously. We demonstrate the effectiveness and robustness of our method through a variety of hairstyles and compare with state-of-the-art hair modeling algorithms.
@article{15-SIG-Hairbooth,author={Hu, Liwen and Ma, Chongyang and Luo, Linjie and Li, Hao},title={Single-View Hair Modeling Using A Hairstyle Database},journal={ACM Transactions on Graphics (Proc. SIGGRAPH)},year={2015},month=aug,volume={34},number={4},}
2014
×
Capturing Braided Hairstyles
Liwen Hu, Chongyang Ma, Linjie Luo, Li-Yi Wei, and Hao Li
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), Dec 2014
From fishtail to princess braids, these intricately woven structures define an important and popular class of hairstyle, frequently used for digital characters in computer graphics. In addition to the challenges created by the infinite range of styles, existing modeling and capture techniques are particularly constrained by the geometric and topological complexities. We propose a data-driven method to automatically reconstruct braided hairstyles from input data obtained from a single consumer RGB-D camera. Our approach covers the large variation of repetitive braid structures using a family of compact procedural braid models. From these models, we produce a database of braid patches and use a robust random sampling approach for data fitting. We then recover the input braid structures using a multi-label optimization algorithm and synthesize the intertwining hair strands of the braids. We demonstrate that a minimal capture equipment is sufficient to effectively capture a wide range of complex braids with distinct shapes and structures.
@article{14-SIGA-Braid,author={Hu, Liwen and Ma, Chongyang and Luo, Linjie and Wei, Li-Yi and Li, Hao},title={Capturing Braided Hairstyles},journal={ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},year={2014},month=dec,volume={33},number={6},}
×
Robust Hair Capture Using Simulated Examples
Liwen Hu, Chongyang Ma, Linjie Luo, and Hao Li
ACM Transactions on Graphics (Proc. SIGGRAPH), Jul 2014
We introduce a data-driven hair capture framework based on example strands generated through hair simulation. Our method can robustly reconstruct faithful 3D hair models from unprocessed input point clouds with large amounts of outliers. Current state-of-the-art techniques use geometrically-inspired heuristics to derive global hair strand structures, which can yield implausible hair strands for hairstyles involving large occlusions, multiple layers, or wisps of varying lengths. We address this problem using a voting-based fitting algorithm to discover structurally plausible configurations among the locally grown hair segments from a database of simulated examples. To generate these examples, we exhaustively sample the simulation configurations within the feasible parameter space constrained by the current input hairstyle. The number of necessary simulations can be further reduced by leveraging symmetry and constrained initial conditions. The final hairstyle can then be structurally represented by a limited number of examples. To handle constrained hairstyles such as a ponytail of which realistic simulations are more difficult, we allow the user to sketch a few strokes to generate strand examples through an intuitive interface. Our approach focuses on robustness and generality. Since our method is structurally plausible by construction, we ensure an improved control during hair digitization and avoid implausible hair synthesis for a wide range of hairstyles.
@article{14-SIG-SimulatedHair,author={Hu, Liwen and Ma, Chongyang and Luo, Linjie and Li, Hao},title={Robust Hair Capture Using Simulated Examples},journal={ACM Transactions on Graphics (Proc. SIGGRAPH)},year={2014},month=jul,volume={33},number={4},}
2013
×
3D Self-Portraits
Hao Li, Etienne Vouga, Anton Gudym, Linjie Luo, Jonathan T. Barron, and Gleb Gusev
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), Dec 2013
We develop an automatic pipeline that allows ordinary users to capture complete and fully textured 3D models of themselves in minutes, using only a single Kinect sensor, in the uncontrolled lighting environment of their own home. Our method requires neither a turntable nor a second operator, and is robust to the small deformations and changes of pose that inevitably arise during scanning. After the users rotate themselves with the same pose for a few scans from different views, our system stitches together the captured scans using multi-view non-rigid registration, and produces watertight final models. To ensure consistent texturing, we recover the underlying albedo from each scanned texture and generate seamless global textures using Poisson blending. Despite the minimal requirements we place on the hardware and users, our method is suitable for full body capture of challenging scenes that cannot be handled well using previous methods, such as those involving loose clothing, complex poses, and props.
@article{13-SIGA-3DSelfPortraits,author={Li, Hao and Vouga, Etienne and Gudym, Anton and Luo, Linjie and Barron, Jonathan T. and Gusev, Gleb},title={3D Self-Portraits},journal={ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},year={2013},month=dec,volume={32},number={6},}
×
Structure-Aware Hair Capture
Linjie Luo, Hao Li, and Szymon Rusinkiewicz
ACM Transactions on Graphics (Proc. SIGGRAPH), Jul 2013
Existing hair capture systems fail to produce strands that reflect the structures of real-world hairstyles. We introduce a system that reconstructs coherent and plausible wisps aware of the underlying hair structures from a set of still images without any special lighting. Our system first discovers locally coherent wisp structures in the reconstructed point cloud and the 3D orientation field, and then uses a novel graph data structure to reason about both the connectivity and directions of the local wisp structures in a global optimization. The wisps are then completed and used to synthesize hair strands which are robust against occlusion and missing data and plausible for animation and simulation. We show reconstruction results for a variety of complex hairstyles including curly, wispy, and messy hair.
@article{13-SIG-StructureHair,author={Luo, Linjie and Li, Hao and Rusinkiewicz, Szymon},title={Structure-Aware Hair Capture},journal={ACM Transactions on Graphics (Proc. SIGGRAPH)},year={2013},month=jul,volume={32},number={4},}
×
Wide-baseline Hair Capture using Strand-based Refinement
Linjie Luo, Cha Zhang, Zhengyou Zhang, and Szymon Rusinkiewicz
Computer Vision and Pattern Recognition (CVPR), Jun 2013
We propose a novel algorithm to reconstruct the 3D geometry of human hairs in wide-baseline setups using strand-based refinement. The hair strands are first extracted in each 2D view, and projected onto the 3D visual hull for initialization. The 3D positions of these strands are then refined by optimizing an objective function that takes into account cross-view hair orientation consistency, the visual hull constraint and smoothness constraints defined at the strand, wisp and global levels. Based on the refined strands, the algorithm can reconstruct an approximate hair surface: experiments with synthetic hair models achieve an accuracy of 3mm. We also show real-world examples to demonstrate the capability to capture full-head hair styles as well as hair in motion with as few as 8 cameras.
@article{13-CVPR-WideHair,author={Luo, Linjie and Zhang, Cha and Zhang, Zhengyou and Rusinkiewicz, Szymon},title={Wide-baseline Hair Capture using Strand-based Refinement},journal={Computer Vision and Pattern Recognition (CVPR)},year={2013},month=jun,}
2012
×
Chopper: Partitioning Models into 3D-Printable Parts
Linjie Luo, Ilya Baran, Szymon Rusinkiewicz, and Wojciech Matusik
ACM Transactions on Graphics (Proc. SIGGRAPH Asia), Dec 2012
3D printing technology is rapidly maturing and becoming ubiquitous. One of the remaining obstacles to wide-scale adoption is that the object to be printed must fit into the working volume of the 3D printer. We propose a framework, called Chopper, to decompose a large 3D object into smaller parts so that each part fits into the printing volume. These parts can then be assembled to form the original object. We formulate a number of desirable criteria for the partition, including assemblability, having few components, unobtrusiveness of the seams, and structural soundness. Chopper optimizes these criteria and generates a partition either automatically or with user guidance. Our prototype outputs the final decomposed parts with customized connectors on the interfaces. We demonstrate the effectiveness of Chopper on a variety of non-trivial real-world objects.
@article{12-SIGA-Chopper,author={Luo, Linjie and Baran, Ilya and Rusinkiewicz, Szymon and Matusik, Wojciech},title={Chopper: Partitioning Models into {3D}-Printable Parts},journal={ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},year={2012},month=dec,volume={31},number={6},}
×
Multi-View Hair Capture Using Orientation Fields
Linjie Luo, Hao Li, Sylvain Paris, Thibaut Weise, Mark Pauly, and Szymon Rusinkiewicz
Computer Vision and Pattern Recognition (CVPR), Jun 2012
Reconstructing realistic 3D hair geometry is challenging due to omnipresent occlusions, complex discontinuities and specular appearance. To address these challenges, we propose a multi-view hair reconstruction algorithm based on orientation fields with structure-aware aggregation. Our key insight is that while hair’s color appearance is view-dependent, the response to oriented filters that captures the local hair orientation is more stable. We apply the structure-aware aggregation to the MRF matching energy to enforce the structural continuities implied from the local hair orientations. Multiple depth maps from the MRF optimization are then fused into a globally consistent hair geometry with a template refinement procedure. Compared to the state-of-the-art color-based methods, our method faithfully reconstructs detailed hair structures. We demonstrate the results for a number of hair styles, ranging from straight to curly, and show that our framework is suitable for capturing hair in motion.
@article{12-CVPR-HairCap,author={Luo, Linjie and Li, Hao and Paris, Sylvain and Weise, Thibaut and Pauly, Mark and Rusinkiewicz, Szymon},title={Multi-View Hair Capture Using Orientation Fields},journal={Computer Vision and Pattern Recognition (CVPR)},year={2012},month=jun,}
×
Temporally Coherent Completion of Dynamic Shapes
Hao Li, Linjie Luo, Daniel Vlasic, Pieter Peers, Jovan Popovi’c, Mark Pauly, and Szymon Rusinkiewicz
We present a novel shape completion technique for creating temporally coherent watertight surfaces from real-time captured dynamic performances. Because of occlusions and low surface albedo, scanned mesh sequences typically exhibit large holes that persist over extended periods of time. Most conventional dynamic shape reconstruction techniques rely on template models or assume slow deformations in the input data. Our framework sidesteps these requirements and directly initializes shape completion with topology derived from the visual hull. To seal the holes with patches that are consistent with the subject’s motion, we first minimize surface bending energies in each frame to ensure smooth transitions across hole boundaries. Temporally coherent dynamics of surface patches are obtained by unwarping all frames within a time window using accurate interframe correspondences. Aggregated surface samples are then filtered with a temporal visibility kernel that maximizes the use of nonoccluded surfaces. A key benefit of our shape completion strategy is that it does not rely on long-range correspondences or a template model. Consequently, our method does not suffer error accumulation typically introduced by noise, large deformations, and drastic topological changes. We illustrate the effectiveness of our method on several high-resolution scans of human performances captured with a state-of-the-art multiview 3D acquisition system.
@article{12-TOG-DynamicRecon,author={Li, Hao and Luo, Linjie and Vlasic, Daniel and Peers, Pieter and Popovi{'c}, Jovan and Pauly, Mark and Rusinkiewicz, Szymon},title={Temporally Coherent Completion of Dynamic Shapes},journal={ACM Transactions on Graphics},year={2012},month=jan,volume={31},number={1},}
2009
×
Estimating the Laplace-Beltrami Operator by Restricting 3D Functions
Ming Chuang, Linjie Luo, Benedict J. Brown, Szymon Rusinkiewicz, and Michael Kazhdan
We present a novel approach for computing and solving the Poisson equation over the surface of a mesh. As in previous approaches, we define the Laplace-Beltrami operator by considering the derivatives of functions defined on the mesh. However, in this work, we explore a choice of functions that is decoupled from the tessellation. Specifically, we use basis functions (second-order tensor-product B-splines) defined over 3D space, and then restrict them to the surface. We show that in addition to being invariant to mesh topology, this definition of the Laplace-Beltrami operator allows a natural multiresolution structure on the function space that is independent of the mesh structure, enabling the use of a simple multigrid implementation for solving the Poisson equation.
@article{09-SGP-ScreenedPoissonRecon,author={Chuang, Ming and Luo, Linjie and Brown, Benedict J. and Rusinkiewicz, Szymon and Kazhdan, Michael},title={Estimating the {Laplace}-{Beltrami} Operator by Restricting {3D} Functions},journal={Symposium on Geometry Processing},year={2009},month=jul,}